A Review on Sentiment Analysis of Twitter Data Using Machine Learning Techniques
DOI:
https://doi.org/10.5281/zenodo.10791471Keywords:
Hybrid, Lexicon-Based, Machine Learning, Sentiment Analysis, TwitterAbstract
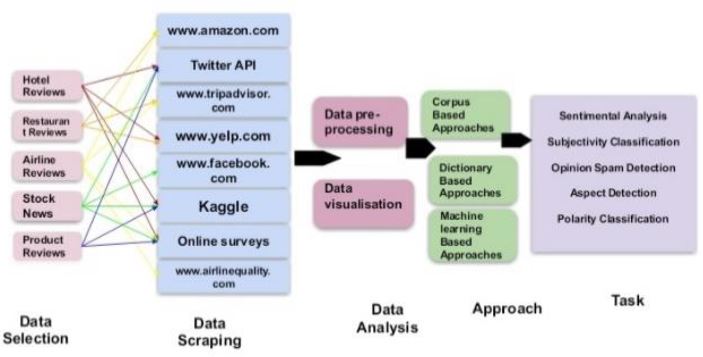
Twitter, a microblogging network, has grown into an ongoing repository of real-time user-generated data, providing a valuable dataset for sentiment analysis. It is an approach that determines the emotional state of data or language. People's opinions may help organizations and governments to acquire information and make decisions based on their perceptions. For instance, when you want a greater understanding of customer sentiment, you can begin by looking at customer feedback underneath what they bought or comments under your company's post on any social media platform. Sentiment analysis determines that a particular text expresses negative, pleasant, or neutral feelings. It's a type of analysis of texts that employs NLP and machine learning. Sentiment analysis employs NLP, analysis of text, computational linguistics, and biometrics to systematically detect, extract, measure, and investigate emotional states and subjective information. This paper provides a thorough review of Twitter Data Sentiment Analysis Using ML Techniques. It covers traditional ML algorithms like random forest, Logistic regression, Naive Bayes, SVM, and decision tree, classifiers, as well as complex deep learning algorithms like RNN, LSTM and CNN and as well as hybrid models like ConvBidirectional-LSTM and CNN-LSTM. Finally, the limitations of Twitter sentiment analysis are examined to suggest future directions.
Downloads
Downloads
Published
How to Cite
Issue
Section
License
Copyright (c) 2024 Mantasha Khan, Ankita Srivastava

This work is licensed under a Creative Commons Attribution 4.0 International License.







